


The fingerprints of ideology in science

In the Birth of Biopolitics, Foucault tells the story of how, in the Western civilization, the task of figuring out what's good or bad for society has moved from one organ to another. He mentions the 16th century's "reason of state", the physiocrats laissez-faire, 18/19th century bureaucrat-engineers, up to the neoliberal use of markets as some kind of measuring instrument.
Now our civilization has evolved a separate organ dedicated to the pursuit of truth, known as academia. To decide your policy preferences, trust the experts. Unlike technocrats, academics have no direct power, their role is only to provide an accurate model of the world to be used by everyone else. This doesn't sound so bad: now public opinion is a part of the chain of command and acts as a barrier between academics and executives. But, of course, this barrier only works if people don't trust the experts.

Full-disclosure: I am myself an academic. I am officially part of the Cathedral, looking at you from the narthex. But this blog is an hermeneutics of suspicion blog, and there is no real power structure above us to check that ideological biases are not deflecting our scientific minds. Therefore, we will have to do the checking ourselves.
1. Drawers
So, how can we watch over academia from below? There are signs. Many papers have obvious methodological flaws, p-hacking and questionable sampling. What's reported in the abstract can be totally different from the actual results (when it's not the outright opposite). Authors make mistakes when calculating p-values, and these mistakes, luckily, change the results in the "right" direction. But all of this can be detected by carefully scrutinizing the papers. However, there is one form of bias that is mostly invisible: selective publication. What if researchers just conduct tons of low-quality studies and only publish the ones that go in the right direction? In that case, the published studies will look perfectly fine.
Publication bias (PB) is usually about how journals are looking for exciting positive results, and non-significant findings are relegated to lower-tier journals. As publication is a long and painful process, it's not always worth the effort. The second kind of PB would be when researchers decide to publish a study or not based on whether they like the results. I will call this "ideological bias". It's not that researchers are intentionally trying to manipulate the masses, but rather that researchers would be less inclined to publish something that goes against their own beliefs. What if the results do not support the favourite ideology of the researchers, or journal editors, or reviewers? In this post, I will argue that there are ways to tease apart these two kinds of selective publication.
To detect PB in the first place, the most straightforward approach is, obviously, to get your hands on a lot of unpublished studies and compare them to the published ones. There are a few studies like that. Here is one by Mary L. Smith on sexism from psychotherapists, here is one by L. J. Zigerell on racism in hiring. Both argue that the existent literature is biased and can't be trusted. But can these studies themselves be trusted? If we accept that academics can be skewed by their ideology, we must accept the possibility that Smith/Zigerell are the ones who engaged in selective reporting1. Therefore, even if this method is useful, it is not conspiracy-proof.
In a previous post, conspiracy-proof archaeology, I considered how it would be possible to investigate conspiracies of the past by exploiting technological advances. There is a window of time when technology allows us to measure something, but not yet to engineer it. During this window, it's possible to test conspiracies empirically before the conspirators can tamper with the evidence. This time, we will not dig up any ancient artefacts and parchments. We will, instead, dig into clouds of data points. It turns out that selectively publishing studies with the desired results leaves statistical fingerprints. Dear sociologists, we can see when you do that.
2. Funnels
As all good metascience tools, this one comes from medicine. Back in the 1990s, medical researchers had a problem: there were large meta-analyses showing that a treatment worked, and somehow it still managed to fail to replicate in later studies. The previous results were a collective hallucination created by PB. And this is when Matthias Egger published two papers marking the beginning of the revolution – he found a way to use the scientific method to detect bias in the scientific literature.
This is done by drawing something called a funnel plot. Each study is represented by a point, with the measured effect on the horizontal axis, and the precision of the study on the vertical axis. If everything is right, it should look something like this:

Near the top, you find the most precise studies with the largest samples, so the effect they measure is very close to the real effect. Then, as you go down, the measured effects spread out as precision decreases and experimental error becomes larger. We expect the funnel to be symmetric, centred around the true value: even if the small studies have big measurement errors, these errors should happen in both directions equally2.
Now imagine the researchers have a tendency to publish only the studies that found a large effect. In that case, some of the studies on one side of the plot will be missing, eroding the funnel shape and breaking the symmetry. Here is such a funnel plot from Shewach et al., 2019 (full text) about stereotype threat (the idea that negative stereotypes impair people's performance at tests, like a self-fulfilling prophecy):

Here, the black dots are the published studies. The white dots are not real studies: they are virtual, placeholder studies that were reconstructed using the trim-and-fill method, representing the missing studies that would be necessary to make the funnel symmetric. Clearly, a lot of studies are missing on the right side. We can see the fingerprints of publication bias.
But something is strange. The triangles in the background indicate statistical significance: if a study falls in the light-grey area, it does not meet the classic p<0.05 significance threshold. If it were just about journals rejecting non-significant results, the missing studies would fall in the light-grey area. But here there are many non-significant results that were published (black dots in the light-grey area). On the other hand, there are a lot of missing studies in the statistically-significant region on the right (white dots on white background), which still didn't get published. What gives?
I think the most probable interpretation is that the people who conducted the studies are strongly inclined to believe in stereotype threat, so when they find that negative stereotypes have a positive effect on test performance, they conclude something went wrong and decide not to publish the results.
Honestly, I can't blame them. Put yourself in their shoes: you are a sociologist who just conducted a study on the effect of stereotypes. Contrary to your expectations, after careful examination of your sample (n=40 psych undergrads), you find evidence of stereotypes favouring the minorities3. What do you do? Your conscience tells you the Data has spoken and results shall be published no matter what. On the other hand, if you do publish your study, it might end up in a Jordan Peterson video, then Breitbart, then you get called a pseudo-scientist on Rational Wiki, then this is repeated by Vox, then by Wikipedia citing the Vox article, and then nobody wants to sit next to you at the cafeteria of the Postcolonial Studies department. Better keep the study in the file drawer.
I see funnel plots as the most important development in meta-science over the last decades. They are more than a cool statistical test – not only we have a rare occasion to see academic biases in action, but so far I don't know of any way to fool the funnel plots. The read-only window is still wide open.
4. Cabinet of monstrosities
The next part is just me looking up various controversial issues and picking the worst examples of PB. Yes, this is cherry-picked. Go ahead and do a meta-meta-analysis of my picks if you dare.
To keep things simple, I'll stick to eyeballing the funnel plot and saying “yep, that’s not symmetric”, but obviously, there all kinds of sophisticated things you can do to measure and (partially) correct PB.
Needless to say, funnel plots are not magical: they can raise suspicion, but they are not smoking guns. Take everything with a grain of salt.

Hiring discrimination
Look at this meta-analysis of racial discrimination in hiring (full text):
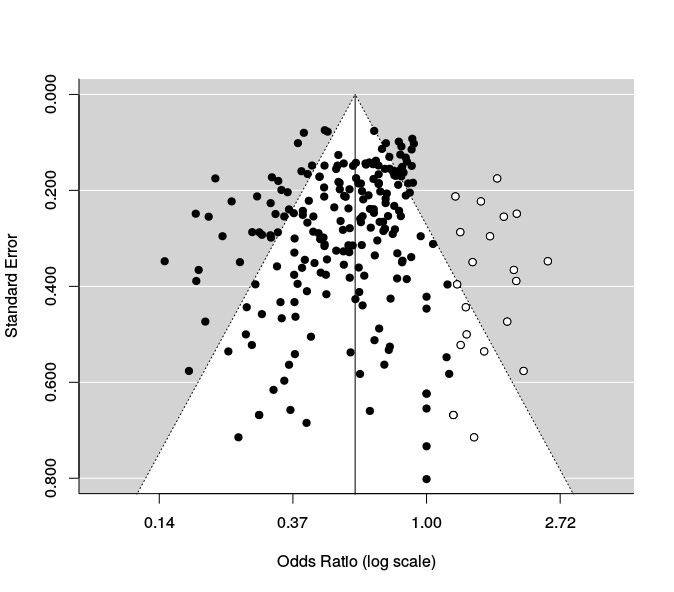
Here again, only the black dots are real published studies. An odds-ratio below 1 indicates that employers discriminate against ethnic minorities. The aggregate effect (vertical line) is clearly below 1, so discrimination against minorities is totally real and serious, and I don’t think the missing studies would have changed much to the overall estimate4. But most of the bias is not from non-significant studies: instead it looks like there is an imaginary border at x = 1.00 beyond which the result is unacceptable for publication. This corresponds to studies (spuriously) finding discrimination against white people – and who would want to be “that guy”?
School grades and IQ
This other meta-analysis (full text, from Gwern, it's always from Gwern) looks at how IQ predicts school grades:

Here, the pattern is upside-down: the more precise the study, the stronger the effect. It looks like studies that found a positive, significant effect are less likely to be published. I suppose it’s more interesting/fashionable/appropriate to say that standard tests are poor predictors of school achievement, resulting in inverse publication bias.
The lead-crime hypothesis
The hypothesis that lead pollution increases crime has been incredibly popular among social scientists since the 70s, because (guess what) poor people are exposed to lead more than rich people. Here is a funnel plot from Higney et al.’s meta-analysis:
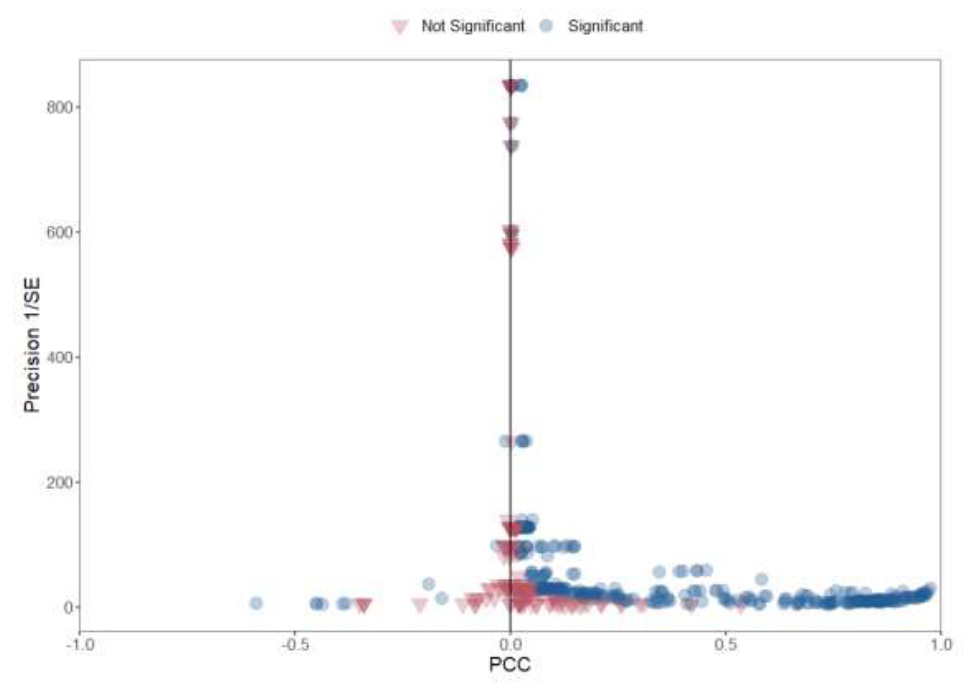
Again, many non-significant studies (in red) were published. According to the authors, the largest and best-controlled studies found an effect close to zero. Now, if we believe them and the effect is really zero, there should be about as many significant studies on either side. But all the significant studies that we'd expect on the left seem to have vanished. Perhaps it's just too awkward to publish a paper arguing that lead pollution reduces crime.
Altogether, there are a lot of plausible cases of publication bias that can't be explained by statistical significance only. The dark art of reading the truth in funnel plots emerged in the late 1990s, but did not take off until a few years ago5. Now, any meta-analysis worth its weight in grants is expected to include one. Will that make academics get their act together? I doubt it.
5. Signals
Obviously, if you came here looking for anti-woke ammunition, then yeah, this post has a lot of anti-woke ammunition. Everyone is biased, and social scientists tend to be woke. Perhaps some portion of sociologists are indeed activists ready to distort the truth deliberately to advance their cause, but I don't think it's frequent. Much more likely, what we are looking at is not ideology as a political agenda, but rather ideology as a tribe signal – it shows you are one of these highly-educated people who defend the underdog and the powerless, and most importantly not one of these middle-classers who still believe the world is meritocratic.
A good class marker must be easy to attack. Recall the lead-crime study above: the evidence for publication bias immediately splits the room in two visible groups – either you conspicuously ignore the funnel plots to signal your total obedience to the Party’s ideology, or you conspicuously point out publication bias to signal how smart and independent you are. Either way, it makes it clear who is and who is not part of your ideological tribe. Thus, Higney’s study turns the lead-crime hypothesis into a culture war toxoplasma. As such, I expect people to mention the lead-crime hypothesis with more fervour than ever.
(Side-note: if you still really really want to use this post as proof that woke = bad: here are a few meta-analyses claiming that the association between minimum wage and unemployment is highly exaggerated by PB, same for economic freedom and growth. Or, if that's your thing, here is one that found researchers exaggerate the correlation between brain size and intelligence. You wouldn’t check bias in your opponents’ research without checking your own tribe first, would you?)
6. Turning out ok
Needless to say, I've only shown terrible cases where terrible bias was found. Not all social sciences are that bad. Sadly, for most of the issues I looked up, PB was not addressed at all, so who knows really?
If you think it is just a problem in the social sciences, not even close . But in medical sciences, PB reflects the fact that medical scientists really want their favourite medical intervention to work. This is bad, but they are not the ones in charge of guiding policy and writing history. If a naive historian from the future tries to figure out what our society was like based on the academic literature of our time, they might think we are the most unfair, horrible civilization to ever exist.
On the other end, even after correcting for possible bias, the overall effects are usually in the right direction. This was the case for the hiring discrimination study above, it's also the case for housing discrimination and many others. Sure, the effect size is distorted, perhaps even distorted in bad faith, and what is reported as the truth still depends on what's fashionable to think among the dominant class. But, in most places through history, a great part of the official literature was about how the King/Emperor/Sultan is so great, virtuous and handsome, and how the lower-status people deserve everything bad that happen to them. Having official institutions that study and acknowledge discrimination against an outgroup is pretty unusual, if not unique. I hope historians of the future will not be too harsh on us.
There is one such study that I trust: Lane et al., 2016 on the effects of intranasal oxytocin. They looked at unpublished studies from their own lab, and found there was a lot of publication bias indeed. "Our initial enthusiasm on [intranasal oxytocin] findings has slowly faded away over the years and the studies have turned us from “believers” into “skeptics”." I don't know many researchers who would have the courage to do this. I don't think I would.
For nitpick enthusiasts: yes, there are special cases where the funnel won't be symmetric even in the absence of PB.
It's not that stereotypes actually favour the minorities (they don't). It's just that the studies are so bad that you would expect occasional studies going in both directions due to random noise.
If you are interested in racism/sexism in hiring, you should also read Hangartner 2021 and Kline 2021. These are too recent to be included in Zirschnt's meta-analysis, but they are so god-damn huge that they should give a fair estimate anyway. TL;DR: racism is real.
As this point, I'd like to praise Jelte Wicherts, the most awesome meta-scientist ever. His work is referenced four times in this post. The study that originally pointed PB in stereotype threat comes from his group, as well as this (failed) replication attempt. His name might ring familiar because he's also the one who found cherry-picking in Lynn and Van Hanen's dataset of average IQ by country. You should be afraid of Jelte Wicherts, because he's coming for you next.
I think the link under "trim-and-fill method" is broken.
"Having official institutions that study and acknowledge discrimination against an outgroup is pretty unusual" -> by definition, if they do that, it's not an outgroup. ISIS is an outgroup.